Getty Images
Until now, even AI companies have struggled to come up with tools that can reliably detect when text has been generated using a large language model. Now, a group of researchers has created a new method for estimating LLM usage across a large body of scholarly writing by measuring which “redundant words” began to appear more frequently during the LLM era (ie 2023 and 2024). The results “suggest that at least 10% of abstracts from 2024 were processed using LLM,” the researchers say. In a preprint paper published earlier this month, four researchers from Germany’s University of Tubingen and Northwestern University said they were inspired by studies that measured the impact of the COVID-19 pandemic by tracking excess mortality compared to the recent past. Taking a similar look at “word overuse” after LLM writing tools became widely available in late 2022, the researchers found that “the emergence of the LLM led to a sudden increase in the frequency of certain stylistic words” that was “unprecedented in both quality and quantity.”
Dive into it
To measure these vocabulary changes, the researchers analyzed 14 million paper abstracts published on PubMed between 2010 and 2024, tracking the relative frequency of each word as it appeared each year. They then compared the expected frequency of these words (based on the pre-2023 trend line) with the actual frequency of these words in abstracts from 2023 and 2024, when LLMs were widely used.
The results discovered a number of words that were extremely uncommon in these scientific abstracts prior to 2023 and that suddenly increased in popularity after the introduction of the LLM. For example, the word “dolves” appears in 25 times more documents in 2024 than the pre-LLM trend would expect; the use of words like “showcase” and “underscore” also increased ninefold. Other previously common words became significantly more common in post-LLM abstracts: the frequency of “potential” increased by 4.1 percentage points; “discovery” by 2.7 percentage points; and “fundamental” by 2.6 percentage points, for example.
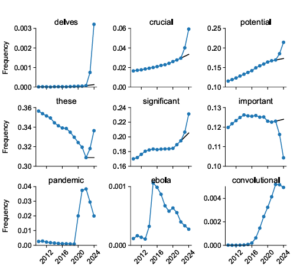
Of course, these kinds of changes in word usage can occur independently of LLM use – the natural development of language means that words sometimes go in and out of style. However, the researchers found that in the pre-LLM era, such massive and sudden year-on-year increases were only seen for words related to major global health events: “ebola” in 2015; “zika” in 2017; and words like “coronavirus”, “lockdown” and “pandemic” in the period 2020 to 2022.
However, in the post-LLM period, researchers found hundreds of words with a sudden, significant increase in scientific usage that had no common link to world events. In fact, while the redundant words during the COVID pandemic were overwhelmingly nouns, the researchers found that the words with an increase in frequency after LLM were overwhelmingly “style words” such as verbs, adjectives, and adverbs (a small sample: ” across, , comprehensive, essential, uplifting, exhibited, insights, especially, particularly, within”).
This is not an entirely new finding – for example, the increased prevalence of “immersion” in scientific papers has been widely noted in the recent past. But previous studies have generally relied on comparisons with “ground truth” human writing samples or lists of predefined LLM markers obtained outside the study. The pre-2023 set of abstracts here acts as its own effective control group, showing how overall vocabulary selection has changed in the post-LLM era.
A complex interplay
By highlighting the hundreds of so-called “tag words” that have become considerably more common in the post-LLM era, telltale signs of LLM usage are sometimes easy to spot. Consider this example of an abstract line evoked by researchers with highlighted markers: “A comprehensive understanding a complex interplay between […] and […] Yippee key for effective therapeutic strategies.”
After making some statistical measurements of the appearance of branded words in individual documents, the researchers estimate that at least 10 percent of post-2022 documents in the PubMed corpus were written with at least some help from LLM. That number could be even higher, the researchers say, because their set could be missing LLM-assisted abstracts that don’t contain any of the tag words they identified.
These measured percentages can also vary widely in different subsets of papers. The researchers found that articles created in countries such as China, South Korea, and Taiwan showed LLM brand words 15 percent of the time, suggesting that “LLMs could … help foreigners edit English texts, which could justify their extensive use”. On the other hand, researchers offer that native speakers of English “can [just] to better notice and actively remove unnatural style words from LLM output,” thereby hiding their use of LLM from this kind of analysis.
Detecting the use of LLMs is important, the researchers note, because “LLMs are notorious for fabricating links, providing inaccurate summaries, and false claims that sound authoritative and persuasive.” But as knowledge of LLM’s telltale markup words begins to spread, human editors can get better at removing these words from generated text before it’s shared with the world.
Who knows, maybe future big language models will do this kind of frequency analysis themselves, reducing the weight of marker words to better mask their output as human. Before long, we may have to call in some Blade Runners to pick out the generative AI text hiding among us.